 |
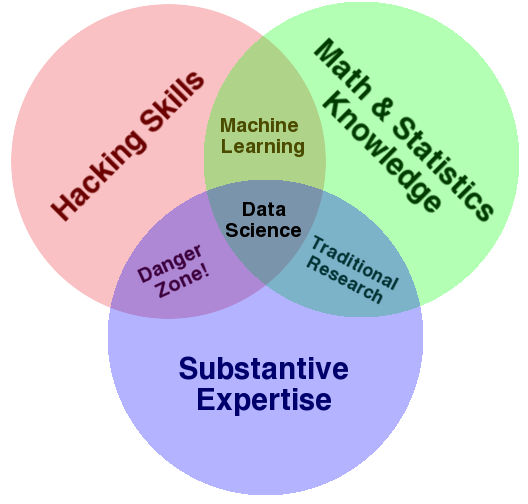
| Drew Conway Data Science Venn Diagam |
I used two texts. First was Stanton Introduction to Data Science, which is used in the Syracuse Data Science certificate program. Second was Introduction to Data Mining with R by Luis Turgo. All of the students were also told to go through Introduction to R prior to the beginning of the course (or as early as possible).
The class started off going through Introduction to Data Science, which included a few introductory chapters to data analysis, and introduction to R and the R Studio IDE. Then were chapters on some basic methods at the basic level such as text processing, review of regression. Then additional methods such as association rules and support vector machines. We then switched to Data Mining with R which were a series of case studies. Each case study had some form of data munging (manipulation) required, with the first one having an involved demonstration of how to handle missing values, either determining the correct value or removing as appropriate. Each case also had a lengthy discussion of the methodologies used, with what each is being used for and a basic understanding of how it worked and its implementation using libraries in use with R (there is a book package, but it has mostly data sets and some functions to assist in data manipulation and visualization.
The assignments were built around individual projects. Their were three presentations, exploratory data analysis, preliminary data analysis, then final. The first two they could work together, but the final one had to be solo as they needed to have individual topics (even if they used the same data sets). The intent was that these assignments would build towards a final goal (but they had flexibility to bail if they wanted to mid-semester.
Probably 1/4 of the students found projects off of Kaggle, which is useful because it has a nice complex data set and comes with a legitimate question. Another 1/4 of the students used public health as a motivating area (University of Pittsburgh is home to Project Tycho, which is a rich dataset of infectious disease in the U.S., also, there is a joint program with the Department of Industrial Engineering and the School of Public Health).
Some problems that came up. First, I discovered that many of the students had an operating assumption that all data was normally distributed, and they constantly made claims that their data was normal. Even when the data was noticeably skewed. This was embarrassing when they would make statistical tests, and the test graphic would include the corresponding normal approximation which was nowhere near the data. I eventually figured out that for many of them, when they took statistics they were constantly fitting normal distributions in their homework data sets, so I explained that their textbook problems were written so that their would be a normal distribution to find.
Another problem was the lack of a hypothesis. Many students started to pick problems that could be solved through linear regression and declared that because it met a p-value criteria they were done. (and in some cases, I recognized the data set as being a teaching data set). But even though they could fit a regression, there was no theory on why the data related in a given way. Essentially, they were pushing data through an algorithm without any subject understanding. Most (not all) of them got the ideas by the end of the second presentation.
A third difficulty was skipping the model evaluation. Most of the methods covered have some parameter that was the analysts choice, so they should have explained how they chose the value of that parameter. Generally, this should have been a discussion of making the tradeoff between closely approximating the observed data and overfitting. Some students skipped this completely (essentially, this is what would happen if you fed data to an algorithm then reported the result using all default values)
One big observation I had by the first presentation was being able to identify the level of programming ability by the choice of projects. I strongly suspect that a number of students were minimizing the programming required. But that became reflected in the level of ambition of the projects. Non-programmers tended to choose simplistic data sets with little variety. I think the difference is the workload. People who could program were able to slice the data available on a multitude of dimensions without regard to scale, since the computer would do all the repetitious work, while those who could not program generally were reluctant to have large sample populations or multiple data sets on the same population.
Things for next time. First, impress on them the need to learn to program. Essentially, the projects from those who could program were so much richer than those who could not (even at a low level of programming skill) that I was embarrassed for those who could not program. Second, I should push harder on the need to have a hypothesis that was driven by domain understanding of the problem. This should be pushed harder from the very beginning to discourage people from merely pushing data through statistical methods and reporting results.
For teaching data mining, I think that the organization of the course needs more methods focus. The principle text was case driven, but that meant that methods were being introduced in a fairly arbitrary sequence. I ended up doing a methodology focused review over the last few weeks. What I should do next times is after the introductory section (Stanton Introduction to Data Science), have the next several lectures be a tour of the classes of data mining methods (regression, classification, clustering, feature selection), then do the case studies. One resource I found useful in this are articles from the Journal of Statistical Software, many of which are focused on R packages that implement classes of methods.
This was a very good course. I wished that the students did more participation (by the final presentation, there were some points that were given based on shear quantity of comments, which several students took advantage of). Some of the projects were much more ambitious than any other done in the MS program. And I have a lot stronger argument about the need for the graduate students to know scientific programming as a skill set.
No comments:
Post a Comment