I gave a talk at the 2025 INFORMS (Institute for Operations Research and the Management Sciences) Analytics+ conference (i.e., industry practice focused as opposed to research focused) on Where Should the Analysts Live: Organizing Analytics within the Enterprise. The talk was a result of many organizations asking if analytics should be managed within companies centralized or de-centralized. One of the topics that came up is the fact that much of the practice of data science is learned on the job. For some people, they may ask if this is the job of universities. I would argue that the practice of data science is so large that this is an impossible ask. I do so from the perspective of someone who for a while was an industry focused professor within an R1 engineering department.
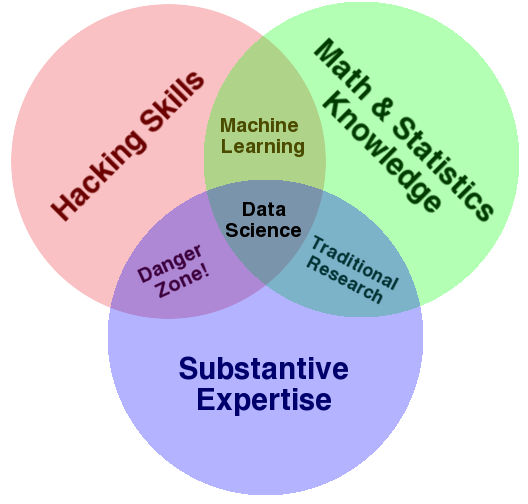
First, what is data science? Drew Conway still gives the best definition that I have seen in the data science Venn Diagram

Math/stats are the full range of analytical methods as well as the scientific method (the 'science' of data science). Hacking skills are the computer programming, software engineering, and data engineering specific to working with data (as opposed to what is generally emphasized by academic computer science). Substantive expertise is the subject domain of the work, but it also includes the specifics of the company such as understanding its markets, its customers, and its strategy.
Math/stats is in principle the domain of our university departments. But university departments are specialists (and research faculty are hyper specialists. There are two problems with expecting university departments to cover the full range of math/stats that may be needed at a particular company. First, university departments focus on a particular domain, so it is not expected that they cover other areas of data analysis that a company may need based on their particular interests. Second, they have limited time and unless you are at a very large state university with a particular mission to cover the full range of a subject area, the faculty of a small or medium size department cannot cover the full range of topics that are associated with a given field of knowledge. So departments create undergrad or graduate programs to cover a foundation, then allow students to specialize (in areas that the department can cover with the faculty they have). As a non-tenure stream professor, I would explain to students that departments hire to cover a wide range of their field, so they generally do not have much duplication. But each department has to make a conscious choice for what they cover and not cover every time they make a hiring decision.
So what is a university promising with their graduates? The base set of knowledge and methods (and methods are more important than knowledge, because it is easy to refresh knowledge, you actually need practice with methods), for STEM (and social sciences) the scientific method that creates understanding through iterative experimentation and statistical analysis of experimental results. And most crucially, the capability of learning a technical area. This ability to learn is arguably the most important part of this whole exercise. Because the world is a big place, and a 17 year old high school student will not be able to predict what the next 40 years will be like. So where a 22 year old college graduate is capable of will be nothing like what she will do over the course of a career. It is hard to develop this ability without college. High school tends to be focused on what you know. And it is too easy in most jobs to just do what you are doing now, unless you already have the experiences of having to learn new/different domains. For example, in most STEM and the social sciences, statistics is a side knowledge domain. But for those who go into data science, the fact that they learned statistics makes learning applied machine learning easy. And the scientific method, while it may not be the thing you think about when you think about engineering or economics, is ingrained into the methods by which they see the world. It is relatively easy to teach skills, it is much hard to teach mindset or the ability to learn new ways to think.
Is there anything different about artificial intelligence? Actually, yes, which makes it easy to learn for STEM and social science trained people, but also dangerous. By definition (see Section 238(g) of the National Defense Authorization Act of 2019) any version artificial intelligence are those which perform tasks without significant human oversight, or that can learn from experience and improve performance when exposed to data sets. In particular, it means that the creators of an artificial intelligence system or model do not have to know how the system that the AI is being added to works. For those in the mathematical sciences (e.g. mathematics, statistics, applied math, operations research, computer science), this is incomprehensible. Even the most theoretical researcher has a core belief that any application of mathematical models involves representing important aspects of the system in mathematical form. But this makes AI (such as machine learning) relatively easy to use in practice, and this has a low barrier to entry. But if someone, like a company, actually has subject matter expertise relevent to the problem at hand, not incorporating that expertise into the model is lost value.
Is it enough to be able to learn new skills as needed? No, we also have to be able to learn to think differently. The most prominent example is Generative AI. For those who only have knowledge and skills, Generative AI is a completely new thing. For those who are able to come up with new ways of thinking, Generative AI a combination and extention of deep neural nets, natural language processing, and reinforcement learning trained on the published internet. And its strengths and weaknesses are not random facts akin to gotchas, but are based on characteristics related to its origins. And knowing that makes a world with Generative AI different, but something that we can use. This past week I went to a seminar on quantum computing. The mathmatics are completely beyond me. but I could understand enough to recognize the reason for its promise, what is lacking, and some sense of what are some key intermediate steps that have to happen if it ever reaches the promise that many talk about. And this practice of being faced with completely new subject domains is something I do frequently.
So what can companies expect from the graduates that come from their university partners (whether through former relationships or merely through hiring in the community). Sometimes it is a collection of specific skills. But more important, a college graduate comes with a testiment that person is able to learn a range of skills and knowledge that are part of a cohesive whole and put them to use. And having done so once, will be able to do it again over a 40 year career.